Gigazineが「HDD約3万5000台を運用した実績からSeagate製品の圧倒的壊れっぷりが明らかに」って記事で紹介してたのが、Backblazeというオンラインストレージ屋さんのブログ。で、そのエントリーのタイトルは「Hard Drive Reliability Update – Sep 2014」。
HDDベンダーごとに故障率を出している、インフォグラフィックスが掲載されていた。…ご丁寧に、このタグで、このイメージをシェアできるよって書いてあったので、素直に貼るとこんな感じ。
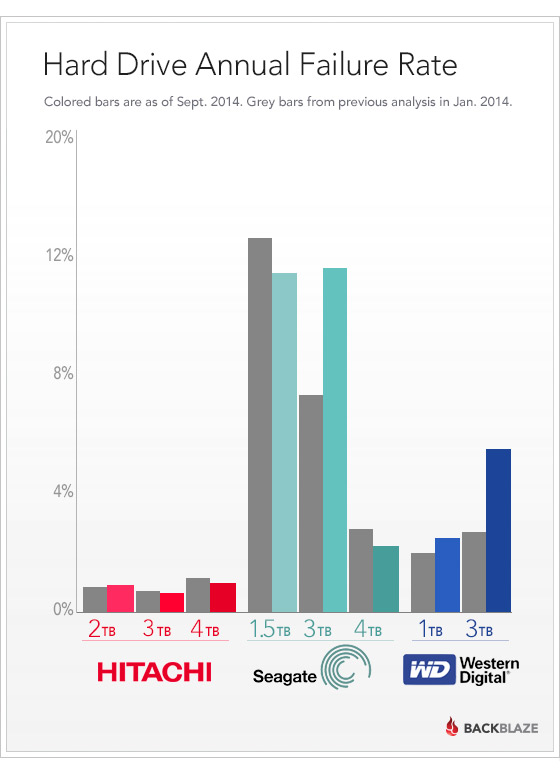
いやー、Seagateさんの故障率の高さが目立つなぁという感じですが、Seagateといえば、ファームウェアのバグの問題が世間を賑わせたわけですが、その頃のモデル(Barracuda.11シリーズ)を使ってたら故障率は高いだろうと思って調べてみたら、SeagateのラインナップのBarracuda.12シリーズでも故障率高いから、うーんという感じ。
じゃぁ、BackblazeはSeagateだけ数多く使っててHGSTとか数が少なければ、故障率も正しくは出てこないよね!と思ったら、別の記事「What Hard Drive Should I Buy?」によれば、Backblazeで使っているHDDはSeagateとHitachiでそれぞれ12,000台ずつって感じだから、特にSeageteが数多いわけでも、HGSTが少ないわけでもないらしい。
で、この1月の記事では、こんな結論を出している。
We are focusing on 4TB drives for new pods. For these, our current favorite is the Seagate Desktop HDD.15 (ST4000DM000). We’ll have to keep an eye on them, though. Historically, Seagate drives have performed well at first, and then had higher failure rates later.
Our other favorite is the Western Digital 3TB Red (WD30EFRX).
まぁ、WesternDigitalのRedシリーズも使うけど、Seagateも長く使うと故障率上がるものの、最初は性能いいしなぁということらしい。RAID等で保護されていれば故障した際にはHDD交換すれば済むけど、堅牢だけど、遅いHDDを並べても性能がでるわけでもないしなぁ。
そんなHGSTの3.5インチHDD事業は東芝に買収されたことを思い出すと、Toshibaの故障率の推移はどうなっていくのか、ちょっと興味深い。今後もbackblazeにはHDDの故障レポートを公開して欲しいな、と。





